
0. 几种优化算法关系


1. 梯度法(Gradient Descent)
1.1 原理
目标函数的梯度:
梯度法基于目标函数的梯度信息进行迭代优化。对于目标函数
,梯度 表示了函数在某点 处的变化率和变化方向。梯度的方向是函数增长最快的方向,而梯度的负方向则是函数下降最快的方向。 迭代更新规则:
梯度法通过迭代更新当前解
的值,使其朝着目标函数下降的方向移动。更新规则通常如下所示: 其中, 是第 步的解, 是下一步的解, 是学习率(也称为步长,为一个常数),控制了每一步迭代中移动的距离。 梯度法实际上是一个最朴素的算法,是后续很多算法的基石
1.2 算法步骤
初始化参数:选择合适的初始参数值
计算梯度:计算目标函数关于参数的梯度
。 更新参数:根据梯度的反方向调整参数值,更新参数
,以减小目标函数的值。更新规则为: 其中, 是学习率(步长),控制参数更新的幅度。 收敛判断:判断是否满足停止条件,例如达到最大迭代次数、目标函数值变化小于阈值等。
迭代:若未满足停止条件,则重复步骤 2-4,直到满足停止条件为止。
1.3 代码实现
1 | import matplotlib.pyplot as plt |


2. 最速法(Steepest Descent)
2.1 原理
最速法其实与梯度法非常非常类似,唯一区别在于最速法的步长
本质:
最速法是梯度法的一种实现
是用线性函数去近似目标函数
最速下降法可以被解释为在每一步迭代中使用当前点处的线性函数(梯度)来近似目标函数,并沿着该线性函数的反方向进行搜索
优点:
迭代过程简单,计算量和存储量小;
算法开局时函数值一般下降的很快,可以很快的靠近最优解的邻域。
缺点:
- 相邻两次迭代方向的正交性 (精准线性搜索定理) 导致锯齿现象,不适用于算法收敛。
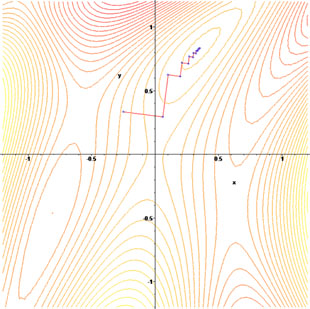
2.2 算法步骤
初始化:
- 选择初始点
- 设定停止条件
- 最大迭代次数
- 选择初始点
计算梯度:
更新参数:
其中, 是学习率(步长),利用一维搜索确定 收敛判断:
- 若
小于预先设定的阈值 ,则停止迭代 - 若 达到最大迭代次数,则也停止迭代
- 若
迭代: 重复2-4
3.3 代码实现
1 | import matplotlib.pyplot as plt |


3.牛顿法(Newton Method)
3.1 原理
由于最速下降法速度慢,Newton引入二阶梯度加速,通过求其Hesse矩阵,一步到位直接求到极小点
牛顿法的原理是基于使用一个二次函数去近似目标函数,然后精确地求出这个二次函数的极小点作为新的迭代点,从而逐步优化目标函数的过程
二次函数的选取:牛顿法通过在当前点处使用目标函数的二阶泰勒展开式来构建一个二次函数作为近似。在点
处,目标函数 的二阶泰勒展开式为: 其中,
是目标函数在 处的梯度, 是目标函数在 处的Hessian矩阵。 迭代方向的选取:牛顿法的关键在于求解二次函数
的极小点,作为下一步迭代的方向。通过令二次函数的一阶导数为零,即 ,解出极小点所对应的 值,即为牛顿方向。 迭代更新:一旦求得牛顿方向
,将其应用于当前点 ,即 ,得到下一次迭代的点 。 收敛性:如果初始点选择得当,且目标函数在局部区域内表现得足够光滑,那么牛顿法往往能够快速收敛到局部极小值点。这是因为牛顿法具有至少二阶收敛速度,即每次迭代都会更快地逼近极小值点。
总结,牛顿法利用二次函数近似目标函数,并通过精确求解二次函数的极小点来指导迭代方向,以加速目标函数的优化过程。
- 缺点:
可能不正定,导致 可能不是下降方向 可能是奇异的,导致 无解 计算量过大
3.2 算法步骤
初始化:
- 选择初始点
。 - 设置精度参数
,用于控制算法收敛的条件。 - 初始化迭代次数
。
- 选择初始点
迭代过程:
- 计算梯度和Hessian矩阵:
- 计算目标函数在当前点
处的梯度 。 - 计算目标函数在当前点
处的Hessian矩阵 。
- 计算目标函数在当前点
- 解牛顿方程:
- 计算牛顿方向
。
- 计算牛顿方向
- 更新参数:
- 更新迭代点:
。
- 更新迭代点:
- 计算梯度和Hessian矩阵:
判断停止条件:
- 如果
,则算法收敛,停止迭代。 - 否则,将
更新为 ,并回到步骤2。
- 如果
3.3 代码实现
1 | import numpy as np |
- 使用有限差分计算黑塞矩阵实现:
1 | import numpy as np |

3.拟牛顿法(Quasi-Newton Methods)
3.1 前言
由于牛顿法存在
可能不正定,导致 可能不是下降方向 可能是奇异的,导致 无解 计算量过大
的缺点,针对
近似矩阵
对称正定 计算更加简单
3.2 SR1
3.2.1 基本信息
- 名称:Symmetric Rank-One
- 提出者:William C. Davidon
- 时间:1956年
其中:
3.2.2 推导
待补充....
3.2.3 算法步骤
初始令
计算梯度:
计算搜索方向:
更新参数:
- 更新迭代点:
- 更新矩阵:
- 更新迭代点:
判断停止条件:
- 如果
,则算法收敛,停止迭代 - 否则,将
更新为 ,并回到步骤 2
- 如果
3.2.4 收敛性
超线性收敛
虽然不是一般的超线性,但是依然算是超线性的收敛速度(准确来说是n+1 步Q-超线性收敛速度
3.2.5 代码实现
注意此处实际上是阻尼拟牛顿法的实现
1 | import numpy as np |
3.3 DFP
3.3.1 基本信息
- 名称:Davidon-Fletcher-Powell
- 提出者:Davidon、Fletcher、Powell
- 时间:1969年
其中:
3.3.2 推导
待补充....
3.3.3 算法步骤
初始令
计算梯度:
计算搜索方向:
更新参数:
- 更新迭代点:
- 更新矩阵:
- 更新迭代点:
判断停止条件:
- 如果
,则算法收敛,停止迭代 - 否则,将
更新为 ,并回到步骤 2
- 如果
3.3.4 收敛性
收敛性证明目前空缺
3.3.5 代码实现
注意此处实际上是阻尼拟牛顿法的实现
1 | import numpy as np |
3.4 BFGS
3.4.1 基本信息
- 名称:Broyden-Fletcher-Goldfarb-Shanno
- 提出者:Broyden、Fletcher、Goldfarb和Shanno
- 时间:1970年
其中:
3.4.2 推导
待补充....
3.4.3 算法步骤
是的就更新矩阵部分变了,其余一样
初始令
计算梯度:
计算搜索方向:
更新参数:
- 更新迭代点:
- 更新矩阵:
- 更新迭代点:
判断停止条件:
- 如果
,则算法收敛,停止迭代 - 否则,将
更新为 ,并回到步骤 2
- 如果
3.4.4 收敛性
Q-超线性收敛速度
3.4.5 代码实现
注意此处实际上是阻尼拟牛顿法的实现
1 | import numpy as np |
参考
- https://zhuanlan.zhihu.com/p/538910657
- https://zhuanlan.zhihu.com/p/306635632
- https://zhuanlan.zhihu.com/p/338829644
- https://zhuanlan.zhihu.com/p/144736223