1.原理
1.1 闭式
正规方程形式求解,即为直接求
先展开
对
令
上述结果即为求解结果,需要说明的是:特征矩阵𝑿不满秩(即存在特征间的线性相关性),则正规方程求解过程中的矩阵求逆操作可能会导致数值不稳定性。
1.2 梯度下降
模型:
注:
损失函数:
注:
目标:
说明:
损失函数
对
每次根据梯度更新参数:
梯度下降法步骤:
2.Python实现
2.0 导包
1 2 3 4 5 6 7 8 9 10 11 12 import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.impute import SimpleImputerfrom sklearn.preprocessing import OneHotEncoderfrom sklearn.model_selection import train_test_splitimport time%matplotlib inline %config InlineBackend.figure_format = 'svg'
2.1 读取数据集
1 2 3 4 5 6 df = pd.read_csv("./housing.csv" ) print (df.head())print (df.info())
2.2 数据探索
2.2.1 数据分布情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 i = 2 fig, ax = plt.subplots(3 , 3 , figsize=(18 , 18 )) sns.scatterplot(data=df, x="longitude" , y="latitude" , size="median_house_value" , hue="median_house_value" , ax=ax[0 ][0 ]) for col in df.columns: if col == "longitude" or col == "latitude" or col == "ocean_proximity" : continue sns.histplot(data=df[col], bins=60 , kde=True , ax=ax[(i - 1 ) // 3 ][(i - 1 ) % 3 ]) i = i + 1 sns.countplot(data=df,x="ocean_proximity" ,ax=ax[2 ][2 ])
2.2.2 数据之间关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 sns.displot(data=df,x="housing_median_age" ,hue="ocean_proximity" ,kind="kde" ) df.groupby('ocean_proximity' )['housing_median_age' ].describe() sns.displot(data=df,x="housing_median_age" ,hue="ocean_proximity" ,kind="kde" ) df.groupby('ocean_proximity' )['median_house_value' ].describe() sns.pairplot(data=df.select_dtypes(include='float64' ), kind='reg' , diag_kind='hist' ) plt.savefig("1.png" ) df_corr = df.select_dtypes(include='float64' ).corr() df_corr sns.heatmap(df_corr, cmap="Blues" )
2.3 数据预处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 total_bedrooms = df.loc[:, "total_bedrooms" ].values.reshape(-1 , 1 ) filled_df = df.copy() filled_df.loc[:, "total_bedrooms" ] = SimpleImputer(strategy="median" ).fit_transform(total_bedrooms) filled_df.info() code = OneHotEncoder().fit_transform(filled_df.loc[:, "ocean_proximity" ].values.reshape(-1 , 1 )) coded_df = pd.concat([filled_df, pd.DataFrame(code.toarray())], axis=1 ) coded_df.drop(["ocean_proximity" ], axis=1 , inplace=True ) coded_df.columns = list (coded_df.columns[:-5 ]) + ["ocean_0" , "ocean_1" , "ocean_2" , "ocean_3" , "ocean_4" ] coded_df.head(10 )
2.4 划分数据集
1 2 3 4 5 6 feature = coded_df.iloc[:, :8 ].join(coded_df.iloc[:, -5 :]) label = coded_df["median_house_value" ] Xtrain,Xtest,Ytrain,Ytest = train_test_split(feature,label,test_size=0.3 ) Xtrain.head()
2.5 求解模型
2.5.0 评价指标R^2
1 2 3 def R2 (y, y_pred ): return 1 - (np.sum ((y - y_pred) ** 2 ) / np.sum ((y - np.mean(y)) ** 2 ))
2.5.1 数据标准化
1 2 3 4 5 6 7 8 9 10 11 12 13 def normalize (X ): sigma = np.std(X, axis=0 ) mu = np.mean(X, axis=0 ) X = (X - mu) / sigma return np.array(X) X = np.array(Xtrain).reshape(np.size(Xtrain, 0 ), -1 ) y = np.array(Ytrain).T.reshape(-1 , 1 ) X = normalize(X) y = normalize(y)
2.5.2 闭合形式求解
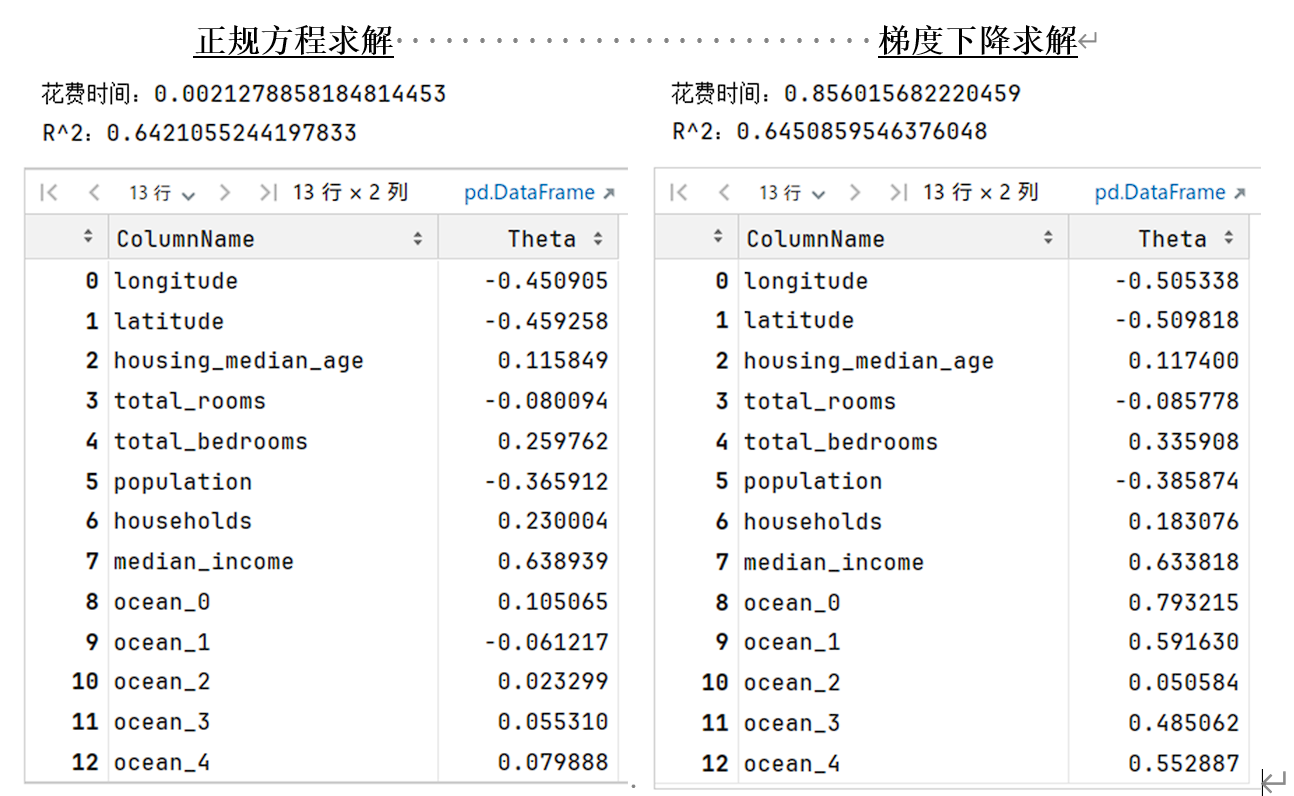
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def Normal_Equation (X, y ): return np.linalg.inv(X.T @ X) @ X.T @ y start_time = time.time() theta_ne = Normal_Equation(X, y) print (f"花费时间:{time.time() - start_time} " )vprint (f"R^2:{R2(y, X @ theta_ne)} " )result_cf = pd.DataFrame({"ColumnName" : list (Xtrain.columns), "Theta" : theta_ne.flatten()}) result_cf
2.5.3 梯度下降求解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def MSE_Loss (y, y_pred ): return np.sum ((y_pred - y) ** 2 ) / (2 * np.size(y)) def GD (X, y, lr=0.01 , epochs=5000 ): m, n = X.shape theta = np.random.randn(n, 1 ) loss = np.zeros(epochs) for epoch in range (epochs): gradient = (1 / m) * (X.T @ (X @ theta - y)) theta -= lr * gradient loss[epoch] = MSE_Loss(y, X @ theta) return theta, loss start_time = time.time() [theta_gd, loss] = GD(X, y) print (f"花费时间:{time.time() - start_time} " )print (f"R^2:{R2(y, X @ theta_gd)} " )result_gd = pd.DataFrame({"ColumnName" : list (Xtrain.columns), "Theta" : theta_gd.flatten()}) result_gd sns.lineplot(x=np.arange(5000 ), y=loss.flatten(), label='Loss Curve' ) plt.xlabel('Epoch' ) plt.ylabel('Loss' ) plt.title('Gradient Descent Loss Curve' )
3.实验结果
3.1 探索数据特征
3.2 求解结果展示